Tel: 07879426788
Email: enquiries@meadowlark.co.uk
Database table structure
In this part we will discuss database tables, their purpose and how they can facilitate management of structured data.
We have developed a tiny simple database here, that has a single table at its core. The table records everything we want to record about tasks. It is fully functional, and needs only one table, because the application is so specialised.
Another type of database that may have only one table is a contacts list. This simple type of database stores basic contact information (name, address telephone, mobile, email, fax etc). It might be a worthwhile exercise, to use what you have learnt creating a tasks database, to create a contacts list. Even with these simple database applications there are circumstances where an extra table or two might be useful.
When to add tables to a database?
A good table design and database stores its information in a highly efficient and succint form. There are no repeating groups of information or very few. We might add tables to eliminate repeating groups, but what do I mean by a repeating group?
A repeating group is some content that appears unchanged many times in a table. In small databases with small amounts of data, this is not a problem, but in larger databases this may not be so. Let me give you an example of how we might benefit from adding a table to our task database to address this and why we might do it.
Our tasks have task types. On my database I have Gardening, Child Care, and DIY and so on, you may have others. Every one of my tasks will have a type, say "Gardening" which will be repeated for every gardening task throughout the database. In a tiny database this is not a problem, but what if there are millions of records all containing this repeated text (Gardening, Child Car or DIY), perhaps accessed by many users concurrently?
That corresponds to a lot of text in the database when aggregated over the whole table, text that could be reduced. This may mean the table is much larger than need be. It means the computer has to work harder to find records for you, the records take up more space, and take longer to sort. and so what can we do to solve this problem?
We could for example replace that repeated text with a code associated with that text, not the text itself. Perhaps the numeric code 1 corresponds to Gardening, and DIY corresponds to the number 2. To achieve this with our database we need to do some more work, not least, create another table. We add a table to our overall design, recording task types that stores Gardening, Child Care and DIY etc along with their replacement codes. The diagram, or entity model in figure "Entities" shows us how we must structure the database to achieve this.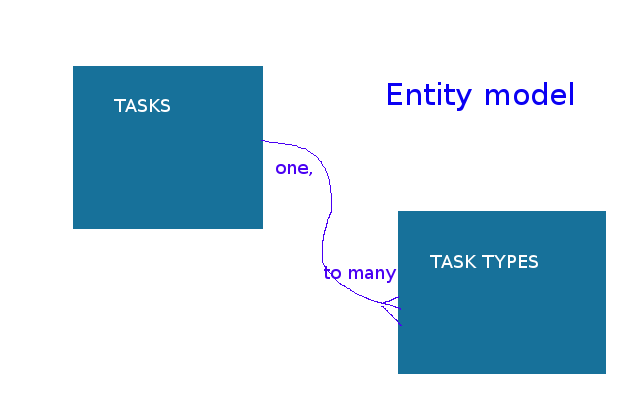
The diagram shows not one but two tables, we have added one called taskTypes. The latter records our list of task types only and almost nothing else. We have added an extra field to the taskTypes database, a numeric code (1,2 or 3) associated with either Gardening, Child Care or DIY etc. What we wish to do is use this numeric code instead of the associated text everywhere the associated text is used. We store a 1 in our two table database where we once stored the text Gardening, we store 2 everytime we would have stored the text Child Care, and so on. Ideally we should change the type of the field that stores the type from text to numeric. Storing small numbers instead of text has important implications for our database.
Now instead of storing say "Gardening" in the types field we store a "1" This is much more compact, taking up perhaps only one byte of storage instead of the nine bytes of "Gardening". All we need now is to remember that a code of 1 always corresponds to the text "Gardining" in any searches sorts, or views. Fortunately databases are good at such things, and can assist this process. To complete this change we need to open the taskType database to the join view and drag a link from its first (numeric) field iTask to the fTask on the list-do.dbf table
A revised simple database design
The diagram below shows a revised entity model (database design) with the added table.
see diagram above.
You will see a line that links the two datbases together. It is called a join. It says in this case that whenever we have a type in the main list-do table, it has a corresponding entry in the taskTypes database - the lookup table - that we need to refer to. Of course we are relying on the datbase management system (Approach) in this case, and/or some code to look after this relationship, as we will see. What this means is that when we produce a report, or run a query on that type field, say Gardening we will search for Gardening, but the database searches for the code for Gardening instead and displays all records that match that code. Likewise in reports. When we produce a report of all our Gardening tasks, the database looks for the code that corresponds to Gardening not the text itself. It may hide this misdirection from us altogether. We have achieved this by adding another database table, populating it with data, then joining it to the list-do table
We can think of tables as small self contained databases in their own right. They tell us something about a small area of interest. Our task database tells us about, well, tasks. In more complex databases, more areas of interest are covered and so more tables are needed. For something as simple as a tasks database, the single table model is still viable, especially if there is so little data that the database is still able to perform at a satisfactory speed. In part 6 we show you how to implement a two table task database
In the next
Previous Next